

Perils of doing mission-critical research with a Large Language Model
Recently, a NY law firm was in the news for the wrong reasons – the firm’s lawyer used ChatGPT to do legal research to find similar historical cases to support his argument and entered the AI’s responses directly in the final brief without manually cross-checking the referenced citations. The result was disastrous for the firm and its lawyers, as the brief cited six non-existent court decisions hallucinated by ChatGPT, causing a lot of confusion and frustration for all the other parties involved and eventually leading the judge to dismiss the case and order a subsequent hearing to discuss potential sanctions on the lawyers. The apologetic lawyer who used ChatGPT said he was “unaware that its content could be false.”
Ironically, the lawyer did not read the fine print.
Underneath the chat window on the ChatGPT website is a tiny disclaimer: “ChatGPT may produce inaccurate information about people, places, or facts.” Instead, the lawyer, who is not the first and certainly not the last person to do this, succumbed to ChatGPT’s fluent and confident fabrications. The lawyer justified his actions by saying he “even asked the program to verify that the cases were real. It had said yes.” Alas, that is not how Generative AI works.
To be clear, the problem is not with ChatGPT or its underlying language modeling technology – which is marvelous in many ways and has plenty of benefits and uses – but with dangerous misunderstandings and misconceptions about such AI systems, as exemplified by the case above and highlighted by the lawyer’s quotes. While Large Language Models (LLMs) such as ChatGPT are capable of fluent, intelligent-sounding dialog, creative writing, and synthesizing complex information, they are inherently flawed in their current design when it comes to producing trusted results. In fact, if there is one thing you can be sure of when using an LLM such as ChatGPT, it’s that it cannot intrinsically verify or validate what it has generated (making the lawyer’s validation question moot).
As a result, using an LLM in isolation as the single source of truth for mission-critical decision making in domains such as legal, healthcare, and finance is a terribly flawed idea, as there is no way to tell whether its response to an open-ended question (where you are not sure of the answer) is correct. The only workaround is to manually cross-check the results yourself against external sources – a task that may be more arduous than directly using the external tools and authoritative sources to answer the question. Ask the opposing lawyers in the case above, who spent needless energy trying to corroborate the six hallucinated citations in the brief.
Is there a way to get accurate answers with LLMs?
At Elemental Cognition, we believe that LLMs can be used for doing mission-critical research, but only when integrated into an overall solution designed from the ground up to produce trustworthy, provably correct results.
EC’s Collaborative Research Assistant, Cora, is our answer to this problem.
Cora takes the best features of LLMs – enabling fluent language interactions, exploring novel hypotheses, and producing synthesized summaries – and combines them with our proprietary Natural Language Understanding (NLU) engine that extracts valuable insights from trustworthy and credible texts, logically connects the dots across multiple information sources, and ensures all answers are evidenced correctly.
The end result is an LLM-powered research tool that is accurate, fast, and reliable.
ChatGPT vs. Cora for Medical Research
A biotech company, on average, spends over $2B bringing a drug to market. To maximize their investment, research teams look for additional diseases where the drug might be effective. In this example, we’ll research a drug that works by blocking an enzyme called IRAK4 to find out if another disease (such as Rheumatoid Arthritis) might be treated by blocking IRAK4.
The research question is whether there is a relationship between the disease Rheumatoid Arthritis (RA) and the enzyme IRAK4 and if inhibiting the latter may alleviate symptoms of the former. Moreover, a researcher with deep expertise in this domain might look for specific, well-established linkage patterns involving the disease and enzyme, such as a connection involving the affected organs, cytokines, and metabolic pathways.
Below is a screenshot of using ChatGPT (as of May 2023) to answer this question. As part of the prompt, we have included intermediate concepts of interest to help guide the AI along the lines mentioned above. The prompt also contains the instruction to “provide valid references from literature and add inline citations to these references.”

Figure 1
As is typical with ChatGPT, the response sounds intelligent and plausible, yet has a critical flaw that undermines its credibility and exposes the general limitations of this overall approach – the citations given by ChatGPT are partially or wholly fabricated. The second and third citations are for papers that do not exist, and the first citation references a real paper but includes incorrect author and journal details. Citations to the literature are meant to reassure the reader that the answer is supported by credible evidence. Citations to non-existent papers or papers that don’t actually support the claims can be worse than no citations at all. The reader is misled to believe that the response is correct and reliable.
Separately, there is a larger problem exposed by this approach – the complete lack of control in the search, filtering, and ranking process. For example, what if the researcher wants more control over the source or time frame of the evidence? There is no mechanism to accurately control for this. Yes, you can include these instructions in the prompt, but there is no guarantee that the LLM will follow such instructions precisely.
Now, let’s try this example with Cora.
The researcher is looking for a causal connection between RA and IRAK4, via linkages involving symptoms, cells, cytokines, and pathways, based on their understanding of the domain and their prior knowledge of what makes a strong causal explanation for this case.
These linkages can be easily specified in a Cora “Research Template”, either graphically or via a Natural Language interface (Cora automatically translates natural language queries into a graphical form). Cora can then directly instantiate the entire template and find answers for ALL concepts along with supporting evidence from trusted medical corpora, such as PubMed, in a few seconds. This is shown in Figure 2.
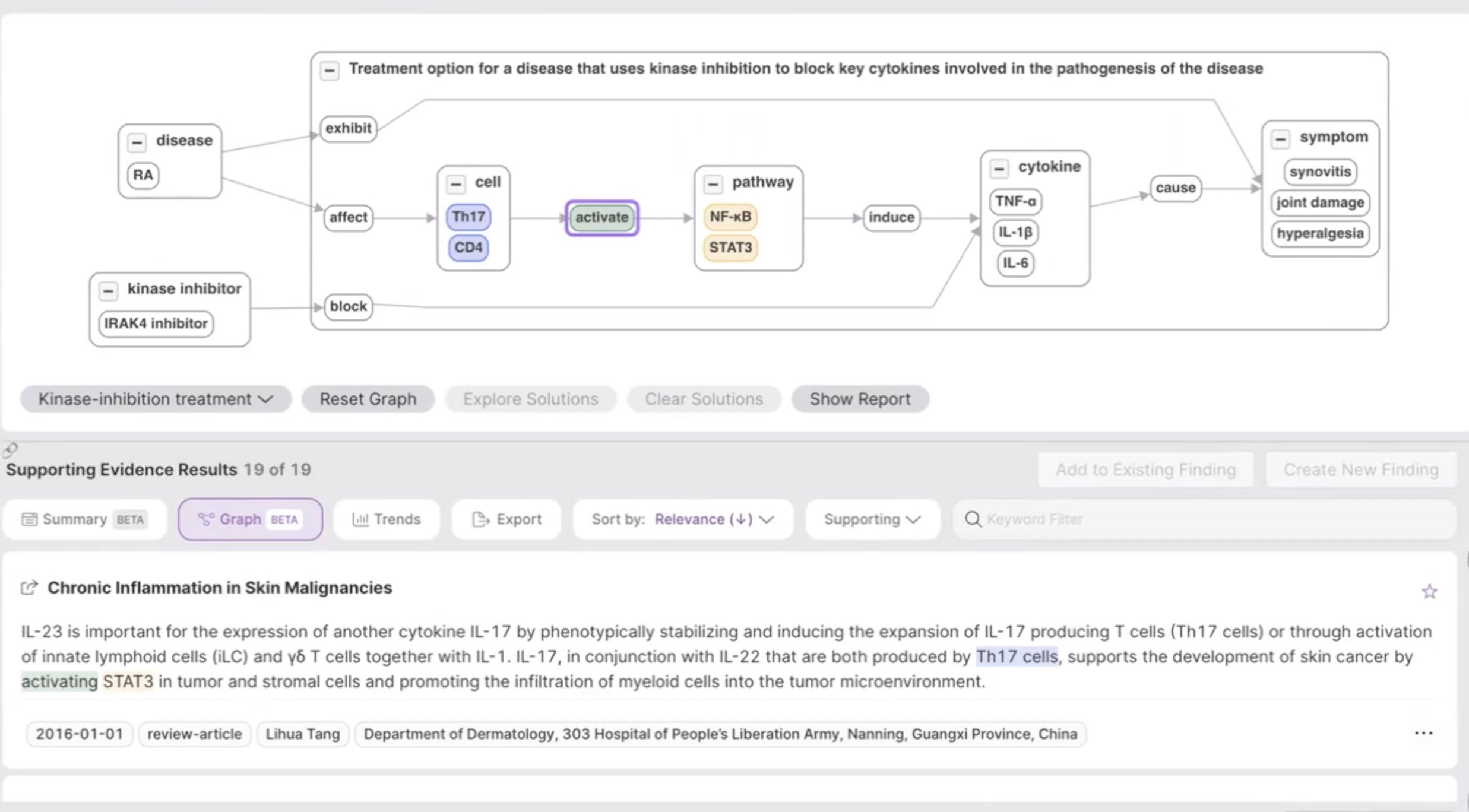
Figure 2: Cora produces answers and evidence for complex multi-relational questions
The user can inspect the answers and evidence for any relationship of interest. Cora pulls answers out of the text automatically, including instances of cells, pathways, cytokines, and symptoms, without requiring a pre-defined schema or ontology. Cora supports filtering the results in various ways, e.g., by date range, authors, or publication journals, and updates the top-ranked answers and corresponding supporting evidence accordingly.
Finally, the user can click the “Show Report” button and get a concise summary of the overall analysis, as shown in Figure 3. This report is generated with the help of an LLM, but grounded to actual evidence snippets for each of the discovered linkages.
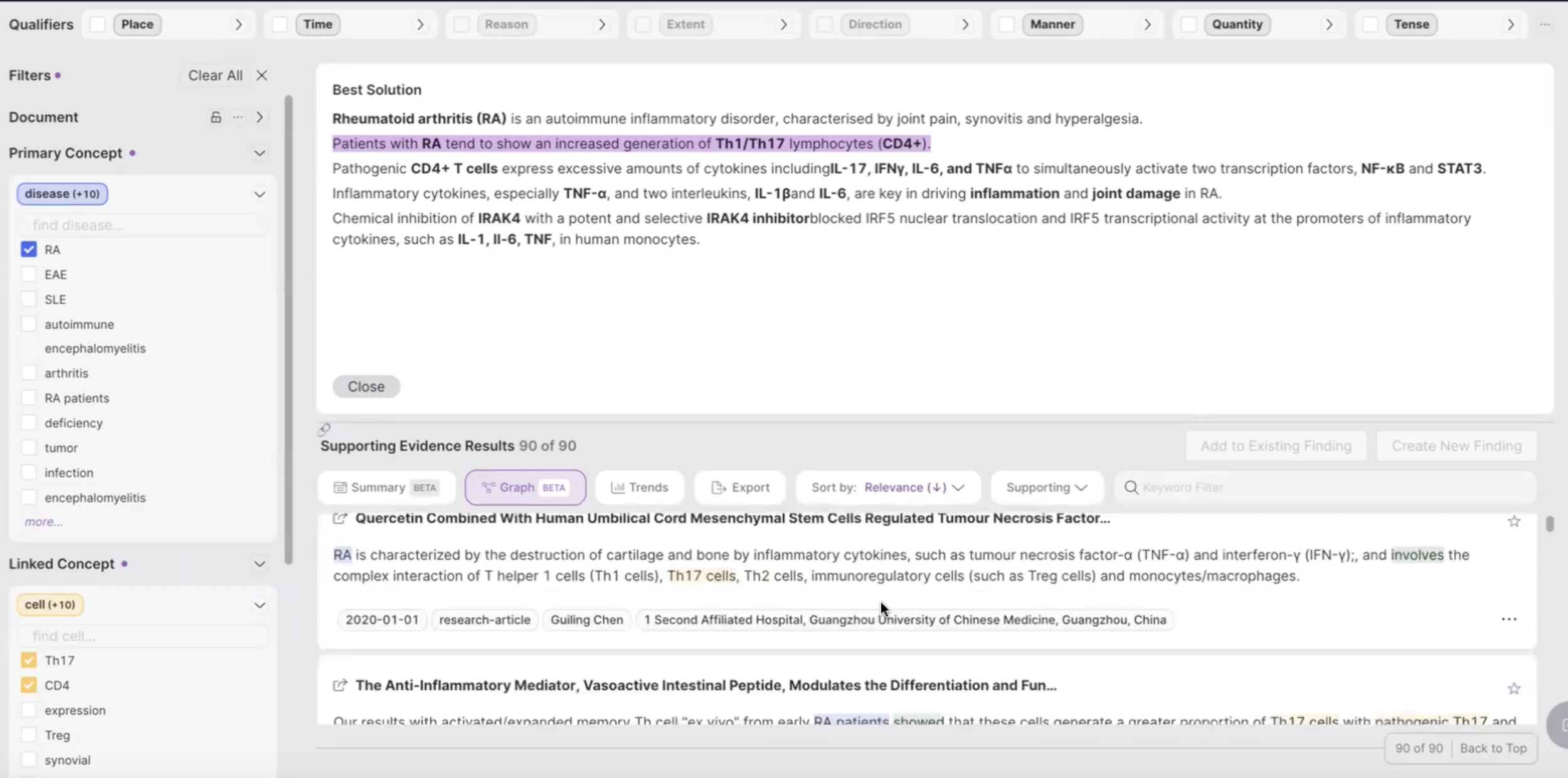
Figure 3: Summary of a causal connection between Rheumatoid Arthritis and IRAK4 Inhibition; each link is grounded in real evidence
The above result, which would normally take days if not weeks of searching and reading through several medical articles to piece together the solution, can now be done in Cora in a matter of seconds or a few minutes. Standalone LLMs, while fast, are simply incapable of delivering the same level of precision, completeness, and validity for such complex multi-relational use-cases.
Note that if the expert did not pre-specify a research template or if the expert’s multi-link template had gaps or incomplete solutions, Cora uses LLMs to generate exploratory hypotheses to fill in the gaps, which are then validated automatically by Cora, thereby combining LLM creativity with Cora’s NLU, search, and grounding capabilities.
In this manner, Cora combines LLM power for language interpretation, creativity, and synthesis with EC’s NLU, structured search, and logical reasoning technology into a collaborative and trustworthy AI research partner. One that works out-of-the-box, supports fluent interactions, and is fast, like ChatGPT, but with the essential added benefits of producing accurate, grounded research results and valid, reliable inferences.
![]()
Developer of a generative artificial intelligence based technology platform designed to empower human decision-making. The company applies large language models (LLMs) in combination with a variety of other AI (artificial intelligence) techniques, enabling users to accelerate and improve critical decision-making for complex, high-value problems where trust, accuracy, and transparency matter.
Recent articles:
Filter



AI for when you can’t afford to be wrong
See how Elemental Cognition AI can solve your hard business problems.